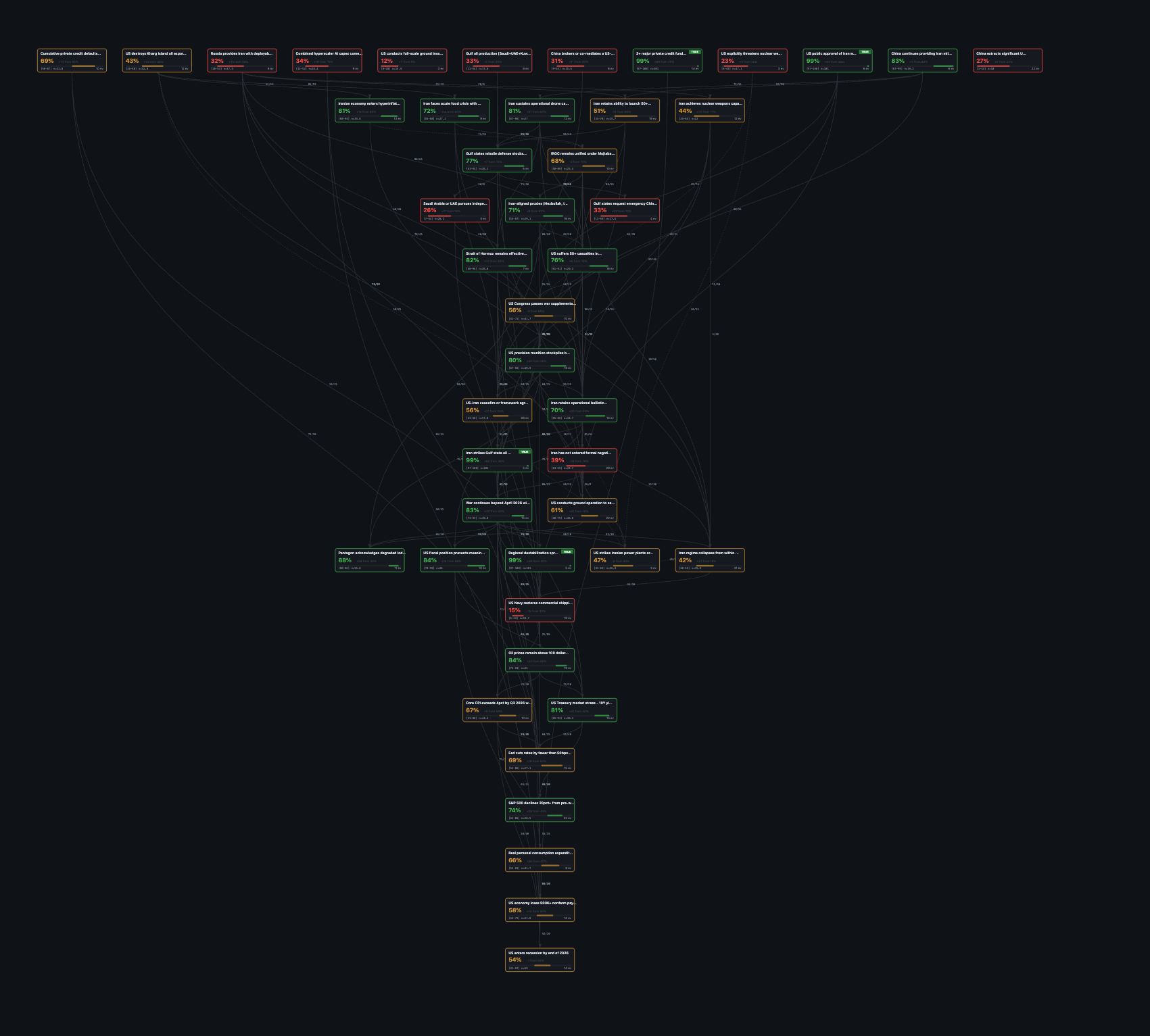
This network is a tree of beliefs about the future.
Unlike a document I read, it's an object I use to think about the world.
LLMs help me build it and keep it updated in a reasonable timeframe.
I run calculations, toggle scenarios like "what if belief X resolves true" and watch probabilities cascade down the branches.
Representing Thought in Carry
Six months ago, I was attempting to build worlds using text documents. I wanted to model possible futures; more precisely, to simulate "what if" scenarios — for example, what if we live in a world with AGI? What if the world warms to 4 degrees?
A recurring issue I had was keeping the LLM reasonable. Simulating a world using an LLM produces a lot of bad attractor states (ie. slop). Outputs eventually tend toward the grandiose or the average. I'd try to salvage any valuable context I'd built up through the conversation into an expanding set of document files. I would then restart the session with the aggregated documents as new context. This would improve outcomes, but often I would surf in and out of local minima on achieving useful results. Ultimately the process lacked a real grounding and I was hesitant to treat it as anything more than a diversion.
This changed after we built Carry. Through experimentation, we've developed a workflow for interacting with LLMs that I'm finding quite fruitful. Carry is a CLI we've built around Dialog-DB, a local-first, embeddable database. When the Iran conflict erupted and it continued to linger, I wondered how things might evolve. Instead of prompting the LLM with aggregate documents about the war, I decided instead to build a model of the war as a Bayesian network (with the LLM as advisor and co-builder). Then that network could become a dynamic object allowing me to explore different scenarios.
Within hours, I could see clearly, with high confidence and evidence-backed explanatory power, how it was going to drag on for months. I've continued to evolve the Bayesian network — it has so far outperformed prediction markets, which are now catching up, on questions like when the war will end and on the likely use of US ground troops.
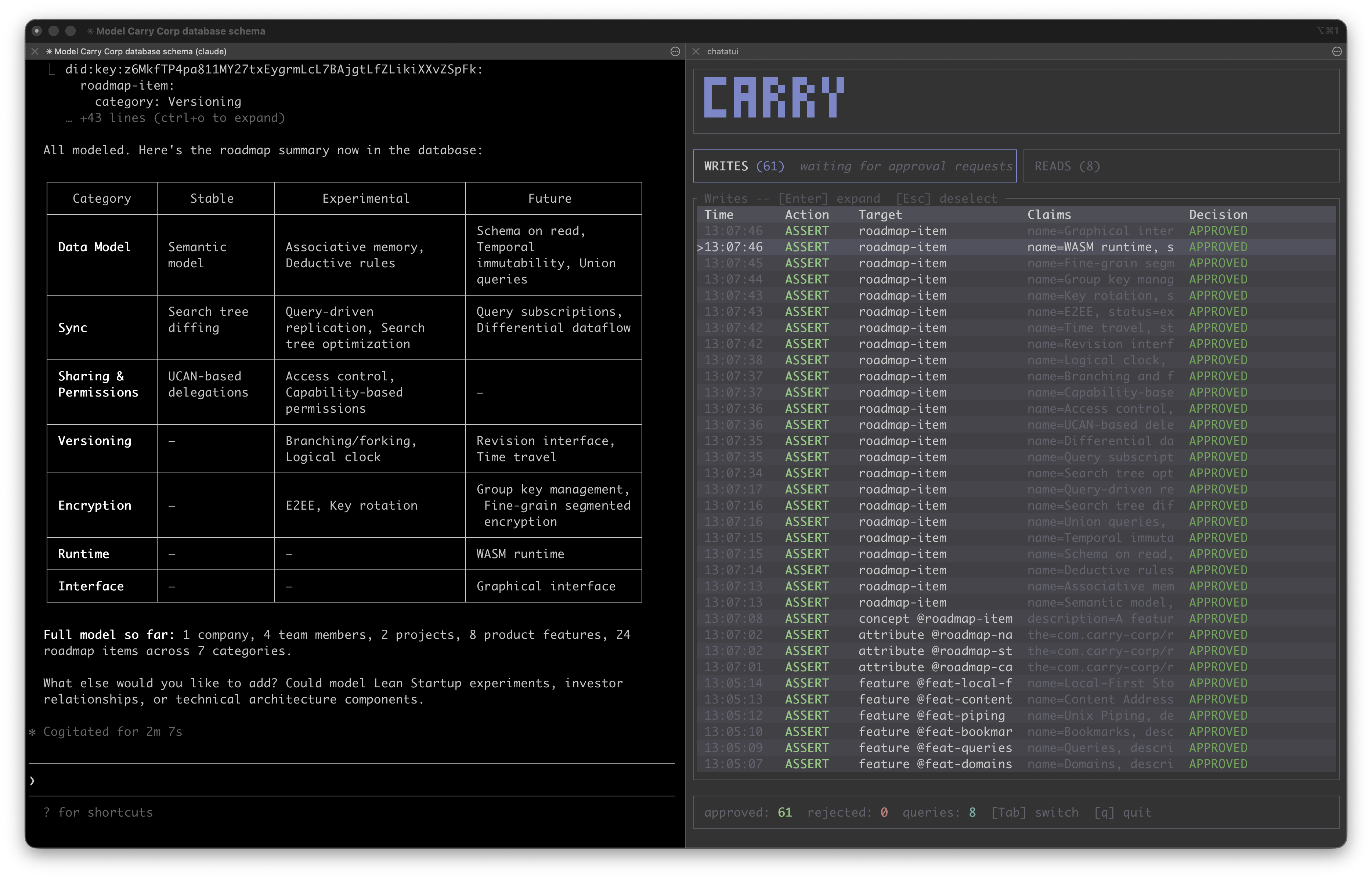
An example of what it's like working with carry in the terminal.
The Prompt is the Artifact
Every word fed into an LLM activates a halo of related concepts. Therefore, if you want to activate the regions of its internal map related to the Iran war and not to Hollywood films, you need to be deliberate about input and the best way to shape that input is through an iterative refinement loop.
Highly condensed, structured representations are effective prompts. This I found surprising, yet perhaps obvious in hindsight, though it is already done in prompt design (bullet points, tables, BIG BOLD HEADERS, etc), we're simply formalizing it.
As context inevitably grows, new relationships and knowledge form that the LLM won't weight correctly. This knowledge should really fold back into the original structured object. That is the core insight, which Andrej Karpathy's latest post on LLM wiki's [1] highlights. Work over an object iteratively (in this case, the wiki) with a model as partner and you start to craft that object into something of quality. AI-assisted knowledge work moves from LLM interprets a thing (blackbox) to LLM recursively reifies a thing (fully legible).
The question becomes how to efficiently fold [2] those new insights back into the structured object? You could keep it as a JSON/YAML, but eventually the file will get large and expensive to read into context on every edit. As size and complexity increase, this starts to look like something that's database shaped. Carry is meant to address exactly this, as its Dialog foundation brings flexible schemas defined at read-time. This means it's simple to evolve structure on the fly. Traditional databases require predefined structure before you add the data, whereas Dialog supports ad-hoc insertion prior to any formalization. Dialog enables exploratory modeling, exactly as our use case demands.
The Artifact is a Knowledge Repository
Iterating over artifacts will encode a network of relations; these become Schelling points. This allows for convergence across sessions that requires no coordination.
For example, the Iranian war Bayesian network encodes 48+ core beliefs linked by probabilistic dependencies. Each belief aggregates hundreds of articles, scraped from the web, and structured with metadata that nudge priors up or down and set confidence intervals. The result is a transparent, evidence-based model that supports traceable inference.
Subsystems retrieve new evidence, while adversarial processes (red/green team agents) work over the structure to identify gaps. The relational structure provides clear guidance for organizing information into its proper place. The whole structure is then efficiently translated into stories outlining the set of scenarios with likelihoods and unknowns.
Carry ensures these relations remain lightweight. Traditional relational databases fail here because they impose friction every time they force you to think about the database. You may have one artifact and another artifact being assembled in parallel and now you need to connect them together, causing schema resolution problems (something schema-on-read sidesteps entirely). I've tried to follow the above workflow in SQLite to test and I got boxed in nearly right away. I don't want to think about how to do migrations when all I care about is connecting ideas together.
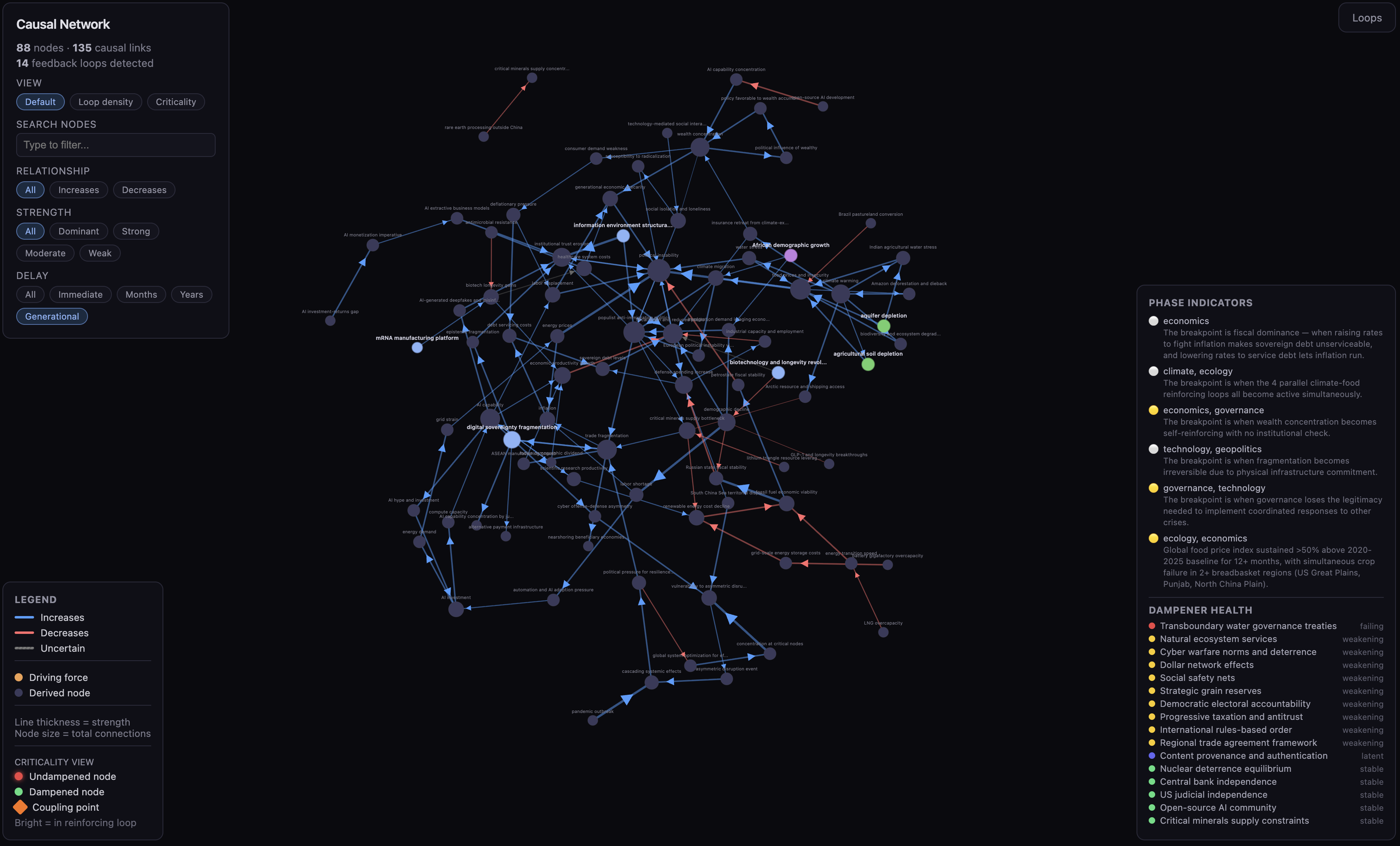
An example model inspired MiroFish running Monte Carlo simulations to trace branching scenarios. Much more token efficient!
Using Computation to Build a World
When knowledge is queryable, it becomes accessible to programs, allowing for computation to imbue data with dynamism.
Agents can add updates, then run programs to validate consistency with defined constraints. Building in this way makes your knowledge accessible to general computation. Run computations in the background, reactively propagate changes or build interactive visualizers on-demand.
In my Bayesian network, there are programs to compute probability propagations whenever evidence updates. Background processes search the web for further evidence. A visualization system shows me the full network as an interactive structure.
Again, conventional database systems cannot easily fit into this workflow because I don't know the shape of my data upfront. Every new module of computation forces me to architect another migration when all I should have to do is express how to consume it. When every new program risks a migration or schema conflict, a flexible data substrate is absolutely required.
The Humane Representation of Thought
Why are we still simulating paperwork, when we have technology that can simulate worlds? Reflecting on this workflow brings me back to Bret Victor's mid-2010s research [3]: using the dynamic medium to reinvent the representation of thought itself (implying that dynamic mediums are mainly used to emulate or extend static representations from an older era of paper).
A large part of the frustration toward LLMs is a consequence of their unintelligibility. Technology should enhance our understanding of the world, not erode it and when we engage in symbolic, visual, tactile and spatial reasoning systems simultaneously in a dynamic medium, we powerfully improve human cognition itself. These richer representations require laborious formalizations of the underlying data that LLMs can now arrange rapidly in concert with human authors. Such knowledge repositories may become a shared epistemic substrate that brings out the best capabilities of both human and machine.
Discuss on Bluesky
Discuss on X
References
- Andrej Karpathy. Post on X (Twitter). 2025. Available at: https://x.com/karpathy/status/2039805659525644595
- Folding Context. Squishy Computer. Available at: https://newsletter.squishy.computer/p/folding-context
- CDG Research Agenda. Dynamicland. 2014. Available at: https://dynamicland.org/2014/CDG_Research_Agenda.pdf